
The previous versions of MLCommons® MLPerf ®Storage (v0.5 and v1.1) focused on ingestion for training data-intensive models like 3D U-Net, ResNet-50, and CosmoFlow. The new checkpointing workload is focused on addressing the backup and recovery speed for training, with a focus on LLMs on scale-out systems.
In this blog, we’ll cover the motivation for checkpointing, how failure rates of AI systems depend on the scale of the cluster, the details of how the workload is run, and how to interpret the results of this new workload.
Failures Halt AI Training Clusters
AI training today is typically a synchronous process. In particular, as a model is being trained on a large cluster, every participating member in the cluster is using the same set of weights. Conceptually, each node will read in data and perform calculations, and then all the nodes will share their calculations to update the weights of the model. The weights must be updated across all nodes before starting the next set of calculations.
Synchronous training makes the entire process much more predictable and reproducible for machine learning researchers and engineers. One downside of synchronous training is that straggler nodes can limit the progress of training jobs. In particular, the failure of a single component that prevents the work of a single node from contributing to the model update results in a cluster-wide stall of the training job.,
Server uptimes are typically measured in months if not years, so failures are often not a major consideration. However, two things set AI training apart from traditional enterprise or cloud workloads.
First, the systems in AI training systems are typically run at maximum performance for their entire lifecycle. This usage model and utilization result in higher failure rates than in traditional systems.
Second, AI training is typically synchronous while traditional workloads are decoupled. If a traditional web server fails, its load can be easily transitioned to another web server. However, due to the synchronous nature of AI training, the failure rate of a cluster scales with the power of the number of components. For example, if a cluster of 100,000 accelerators has a failure rate of R for a given accelerator, then the failure rate of the cluster is R100,000. For large-scale systems, even a tiny component failure rate can be highly problematic.
Checkpointing Ensures Forward Progress
The MLPerf Storage Working Group has developed a model of the failure rates of AI clusters and estimates of the target checkpoint intervals based on real-world data. Meta’s “Llama3: Herd of Models” paper provides information about failure rates seen at scale (https://arxiv.org/abs/2407.21783). In that paper, Meta describes the training cluster used (16,000 accelerators) to train the Llama 3 models. The training process took 54 days and encountered 419 failures. The majority of these failures scale with the size of the cluster, and assuming the failures are uniformly distributed over time yields a model for the Mean Time Between Failures (MTTF) as the cluster size scales up:
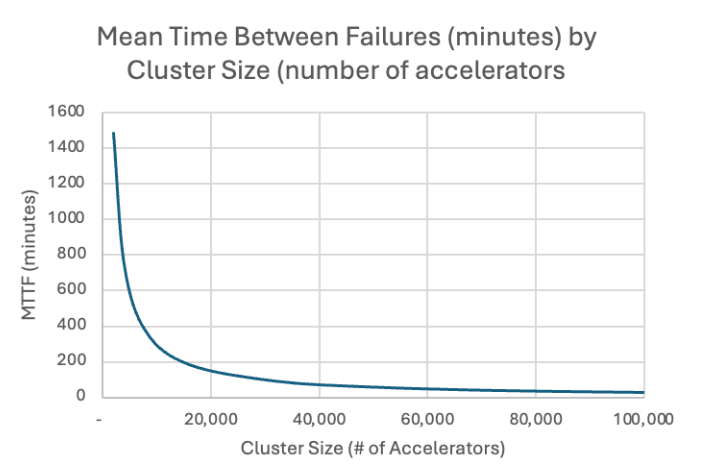
Due to the cluster failure rate scaling to the power of cluster size, MTTF exponentially decreases as cluster size increases. The model correlates fairly closely with Meta’s data for 16,000 accelerators, predicting 7.67 failures per day versus the observed data (7.76 failures/day).
Generally, checkpointing strategies are designed to carefully balance the frequency of checkpointing against the protection. A common rule of thumb with large-scale systems is that losing 5% or less of the progress since the last checkpoint is reasonable. Put another way, there should be roughly 20 checkpoints between expected failures.
The exponential impact of cluster size on failure directly translates into a similar impact on checkpointing. For 16,000 accelerators (which is similar to the size of some clusters that are deployed today), 155 checkpoints per day are necessary, or roughly once every 9.3 minutes. At the scale of 100,000 accelerators, this equates to 967 checkpoints per day or a checkpoint every 1.5 minutes.
Finally, the last metric we want to pull from this model is the time available to perform a checkpoint. First, we wanted to ensure we were taking checkpoints frequently enough to minimize the time between failures. Now, we want to ensure we’re not spending too much time with the cluster stopped while we’re taking checkpoints.
As with most forms of redundancy and data protection, checkpointing is not free – it imposes some overhead on the overall AI training effort. As the frequency of checkpoints increases with cluster size, this overhead becomes more pronounced. To keep the overhead below 5% is increasingly challenging as clusters grow in size. For example, a 16,000 accelerator cluster that checkpoints every 9.3 minutes, the checkpointing process can take 28 seconds. For a larger cluster comprising 100,000 accelerators, this falls to a mere 4.4 seconds. These examples illustrate how increasing cluster size for AI training creates an increasing bottleneck in the storage system.
Checkpointing Workload in v2.0
The new checkpointing workload is implemented to be representative of real systems as much as possible. The checkpoint workload defined here creates an in-memory representation of the model and optimizer state, then uses PyTorch save and load to perform the write and read operations.
For the workload, we define four different model sizes:
· 8 Billion parameters
· 70 Billion parameters
· 405 Billion parameters
· 1 Trillion parameters
The model sizes are intended to emulate the Llama 3 Herd of Models with a 1T parameter model added with extrapolated values to represent larger models currently in development.
For CLOSED submissions, each of the model sizes has a required number of processes for saving or loading a checkpoint. These process numbers represent a reasonable minimum size of a system that can train a model of a given size.
OPEN submissions allow changing the number of processes to a multiple of the model’s defined Data Parallelism (see the table below). This is to represent sharding the model over more hosts, which results in more processes initiating the checkpoint save or load at the same time and with less data per process (the model and optimizer states stay the same size as more data parallel instances are used as the model and optimizer are replicated between data parallel instances).
Each process executing the checkpoint will write one or more large files (100s of MBs to GBs in size) depending on the model size, and benchmark-internal parameters representing the parallelism configuration and the model and optimizer sharding method.
Additionally, there’s an operating mode used only for client-local storage solutions like local NVMe devices called Subset mode. When run in subset mode – regardless of the required number of processes – only eight processes are used.
Subset mode represents using an NVMe drive in each of the accelerator nodes as the first tier of checkpointing storage. Subset mode will perform a portion of the checkpoint depending on the model size.
Finally, to ensure the test is measuring the performance of the underlying storage, a successful checkpoint workload run consists of 10 Save operations followed by 10 Load operations. If the client memory is above a threshold (3x the size of a node’s checkpoint), then the submitter must clear the filesystem caches between the save and load phases.
Table 1 – Checkpointing Parameters by Model Size
| Model | 8B | 70B | 405B | 1T |
| Data Parallelism | 1 | 1 | 2 | 2 |
| Total Processes | 8 | 64 | 512 | 1024 |
| Checkpoint size | 105 GB | 912 GB | 5.29 TB | 15 TB |
| Subset: 8-Process Size | 105 GB | 114 GB | 94 GB | 144 GB |
One important takeaway is the sheer size of the checkpoints. The actual model only accounts for a portion of the data in a given checkpoint. The bulk of the data is actually the optimizer state of the cluster at that point in time.
For example, the checkpoint for the 8 Billion parameter model totals 105GB, and the optimizer state makes up 90GB. For the 1 Trillion parameter model, the optimizer makes up a whopping 13.2TB of the 15TB of checkpoint data.
This helps to put some real sense of scale around the challenge of checkpointing. For a very large model like a 1 trillion parameter training on a cluster of 100,000 accelerators, writing out the 15TB checkpoint every 1.5 minutes results in over 14 Petabytes of writes per day for checkpoints alone.
For synchronous checkpointing, this implies writing 15TB of data in under 5 seconds – averaging about 3.6 TB/s across the cluster or roughly 200GB/s for the entire duration of the training job.
Interpreting the Results
The results of a checkpointing workload will include one or more of the supported model sizes with the associated Save and Load performance scores.
The default metric is throughput (GiB/s) for the operation, with the option to expand the table to see the result as a duration number as well (in seconds).
On the surface, the large reads and writes may seem like a trivial workload, but the large number of processes performing the operations in parallel results in interleaving of data at the physical layer in a way that can inhibit performance in storage systems.
Furthermore, a checkpoint Save or Load is only complete when every process is done. This means that the numbers represented in the results table are based on the time taken by the worst-performing process rather than an average of steady-state performance.
End users and customers will have differing views on the relative importance of Save vs Load. Save operations happen more frequently, which means more chances for a bad save to impact operations, while every Load operation is likely being performed during the most critical time: while the cluster is stopped.
Additionally, comparing the subset and full checkpoint modes with each other is difficult. As executed, the subset mode does not provide full fault tolerance and requires either a secondary storage solution or additional software enhancements by the end user.
Conclusion
In this blog post, we have provided an overview of the motivation for checkpointing as a new workload within MLPerf Storage, the relationship between AI training cluster size and checkpointing frequency and volume, an overview of checkpointing in MLPerf Storage v2.0, and a rough guide on interpreting the results. This is the first industry standard benchmark for checkpointing in AI training and will ultimately help the community understand performance requirements and enable greater optimization and capabilities for the entire ecosystem.
You can read more about the MLPerf Storage v2.0 results on our blog.